Enne, kui andmebaasi loomisega edasi läheme vaatame, kuidas oleks võimalik juba sisestatud andmeid vaadata ja uurida.
Olemasolevate andmete kättesaamiseks sobib päringulause SELECT. Lihtsaim käsk kõigi olemasolevate andmete tabelist kätte saamiseks:
SELECT *
FROM dbo.Laps_tbl
Tulemusena joonistub rakenduse allserva kogu tabelitäis andmeid koos tulpade nimedega.
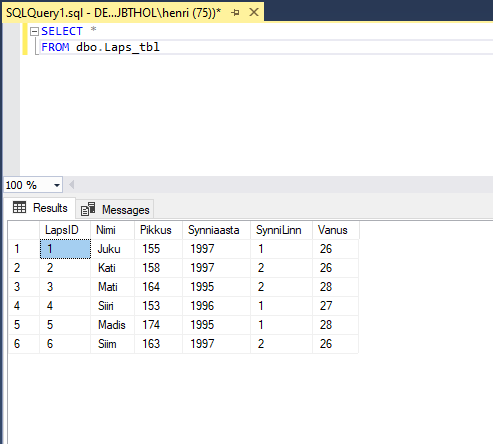
Sellist päringut kasutatakse vaid erandolukordades ning väga väikeste tabelite juures. Reaalses tööolukorras tuleks kindlasti loetleda ülesse kõik väljad, mida soovite vaadata ning seada piirangud ridade arvule!
Järjestamiseks piisab lisaklauslist ORDER BY, millele järgneb tulba nimi. Kui soovime kõik tabelis olevad andmed trükkida sorteerituna nimede järgi võime kirjutada:
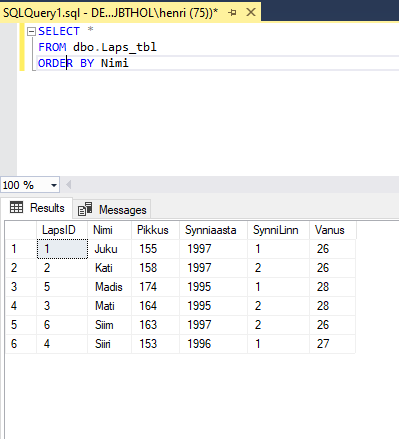
Ja tulevadki andmed nimede järgi sordituna. Et esimeses tulbas olevad id-d näevad juhuslikult segi paisatutena välja, see on täiesti loomulik. Kui sorditakse nime järgi, siis tõstetakse read niimoodi ümber, et eesnimed lähevad tähestikulisse järjekorda. Iga rea andmed aga kuuluvad endiselt kokku. Nii nagu Siiri oli algul 153 sentimeetrit pikk ja sündinud aastal 1996, nii on ta seda ka pärast järjestamist. Ja samuti tema id-number jääb neljaks.
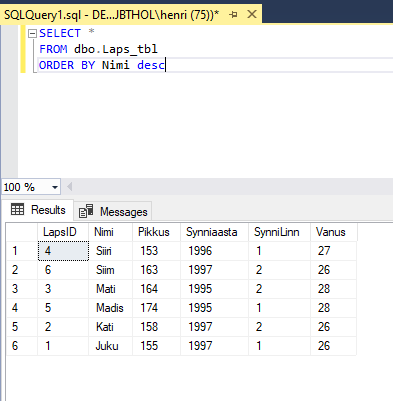
Tahtes sorteerimisjärjekorra muuta vastupidiseks, tuleb tulba nimele lisada tähed DESC (sõnast descending). Ja ongi Siiri esimene ja Juku viimane.
Järjestust määravaid tulpi võib olla mitu. Sellisel juhul tuleb ORDER BY järgi loetleda väljad tähtsuse järgi. Nt võttes sorteerimise aluseks sünniaasta ning seejärel nime saame, et sõnniaastad on sorteeritud kasvavasse järjekorda ning kui samal aastal on sündinud mitu last on nad sorteeritud nimede järgi:

Sugugi alati pole andmete juures vaja kõiki tulpasid näha. Kui soovin vaadata vaid nime ja pikkust võin selle info panna ka SELECT lausesse, loetledes kõik vajalikud väljad SELECT´ i järel.
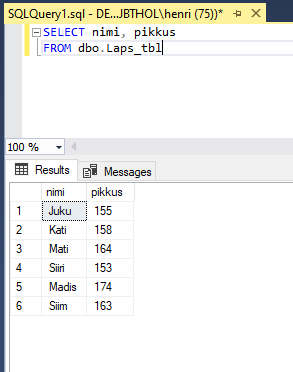
Samuti saab seada piirangu ridade näitamise suhtes. Siin vaid lapsed, kelle sünnilinn on Tallinn e. linna kood on 1
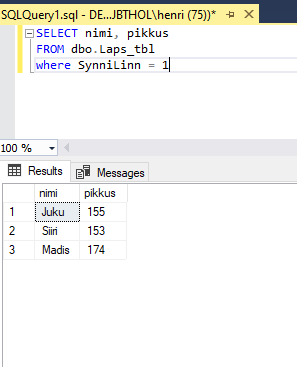
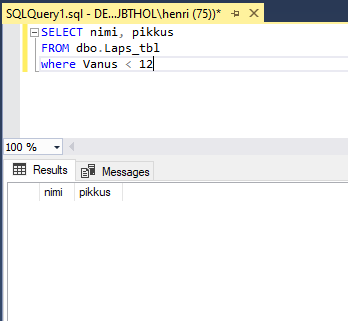
Või vaatame, millised lapsed on nooremad kui 12:
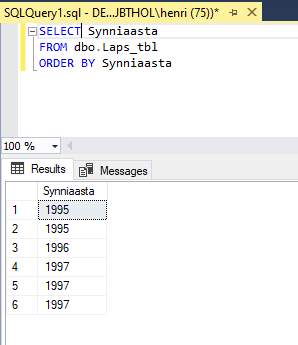
Kui tulemusse tekivad korduvad read saame nendest vabaneda kasutades DISTINCT märksõna. Näiteks soovime välja selgitada milliste sünniaastatega lapsed meil tabelis on? Kui kirjutame SELECT´i ilma DISCTINCT märksõnata saame loetelu, kui kõigi laste sünniaastad, kui lisame DISTINCTI saame kõik erinevad sünniaastad:
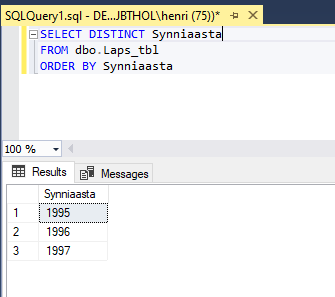
Võime piiranguid seada ka numbrivahemike järgi. Selleks on kaks võimalust:
- Kasutada BETWEEN operaatorit
- Kombineerida kaks võrratust AND operaatoriga
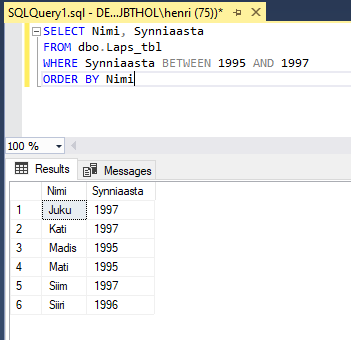
Sama tulemuse saaksime ka järgmise SQL lausega:
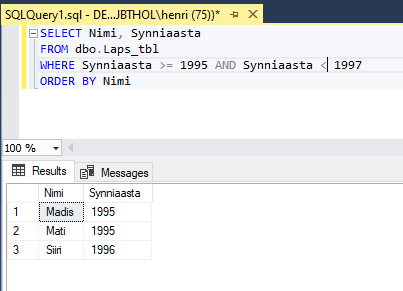
SELECT Nimi, Synniaasta
FROM dbo.Laps_tbl
WHERE Synniaasta >= 1995 AND Synniaasta <= 1997
ORDER BY Nimi
BETWEEN operaatori eeliseks on lihtsus ja ülevaatlikus. Loogikaavaldise kasuks räägib aga paindlikkus – nimelt võime mõnest osapoolest võrduse ära võtta jättes täpsed väärtused välja. Näiteks otsime lapsi, kes on sündinud alates aastast 1995, kuid enne aastat 1997: