Tingimuste kombineerimine
Olemasolevaid tingimusi saab alati omavahel kombineerida. AND nõuab, et mõlemad tingimuse pooled oleksid täidetud, OR seevastu piirdub nõudega, et vähemalt üks tingimustest oleks tõene. Kõigepealt siis nimed, mis lõppevad i-ga ning sünnilinn on Tartu (kood 2)
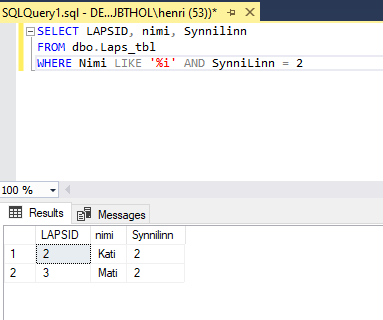
Edasi kõik i-lõpulised nimed pluss veel lisaks kõik, kes sündinud Tartus. Nimesid korduvalt siiski ei näidata. Kuigi Siiri ja Mari vastavad mõlemale tingimusele, on nad nimekirjas siiski ainult ühe korra.
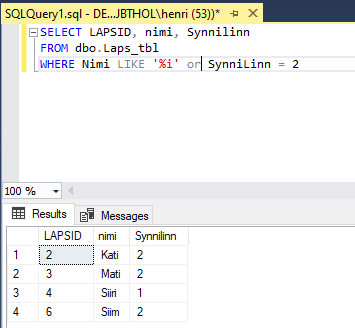
IN
Tahtes ette anda lubatud väärtuste hulka, millele otsitav peab vastama, aitab käsklus IN. Järgnevalt siis tegelased, kelle sünniaastaks on kas 1995 või 1997.
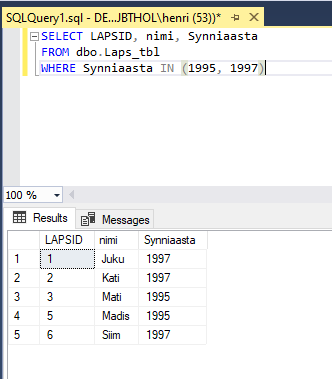
Sama tulemuse saab ka kombineerides OR operaatoriga otsesed võrdused:
SELECT LapsID, Nimi, Synniaasta
FROM dbo.Laps_tbl
WHERE synniaasta = 1995 OR synniaasta = 1997
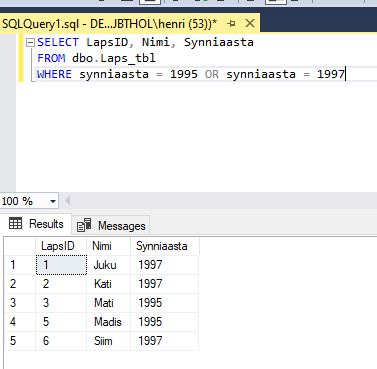
Kuigi tulemus on sama ja SQL Server käsitleb neid päringuid ühtemoodi on IN operaatori kasutamine ülevaatlikum.
NOT
NOT pöörab tulemuse ümber. Ehk siis kõik need lapsed, kes ei ole sündinud aastal 1996.
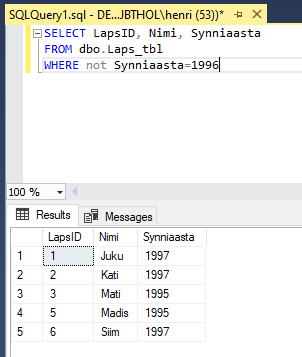
Võimaluse korral soovitatakse NOTi mitte pruukida, sest enamasti peab sel juhul andmebaasimootor vaatama läbi tabeli kõik read, mis on suurte andmemahtude juures küllalt suur töö. Aga kui muidu läbi ei saa, eks siis peab ikka selle sõna kirjutama.
TOP, päringu algusosa
Lihtsalt andmetest ülevaate saamiseks ei ole vaja sageli kõike näha. Samuti, kui soovime viite kiiremat jooksjat või viite vanemat autot, siis on mugav, kui päring kohe annabki meile soovitu kätte, mitte ei pea hakkama ise pead vaevama, kuidas soovitud kohast andmeid võtma hakata. Laste tabelist tähestiku järjekorras kolm esimest nime näiteks saab kätte nii.

Tahtes saada neli vanemat last, tuleb andmed sorteerida sünniaasta järgi.
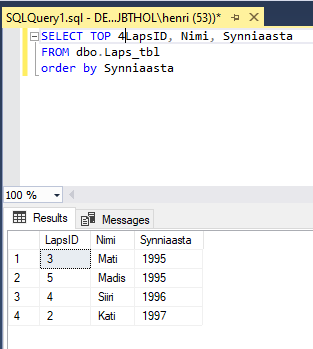
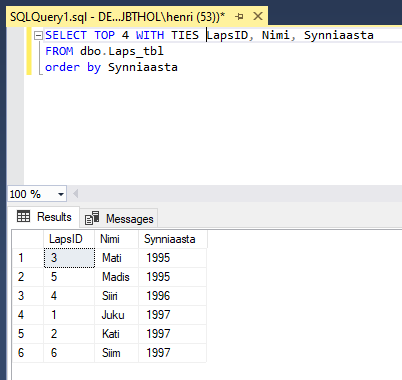
Tekib aga probleem: kuna andmed on salvestatud aasta täpsusega, siis võetakse 1996ndal aastal sündinutest lihtsalt juhuslik komplekt ning ülejäänud jäävad näitamata. Mõnikord pole sellest hullu – saadi juhuslikud tegelased kokku ja sobib küll. Teinekord aga võivad samade tunnustega osalejad porisema hakata, kui üks neist kaasa võeti ja teine mitte. Et saaks kõik ausalt kaasa, kes teistega võrdsed, selleks saab TOP käsklusele lisada WITH TIES. Nii võetakse siin näites vähemalt kolm. Ning kui jagub järjestatava tunnuse alusel viimasega võrdseid mahajääjaid, võetakse ka nemad kaasa.
Lisaks fikseeritud ridade arvule võime määrata ridade arvu ka proportsionaalselt kogu ridade hulgast e. kasutada protsenti. Näiteks võime välja tuua neli protsenti kõige vanemaid lapsi:
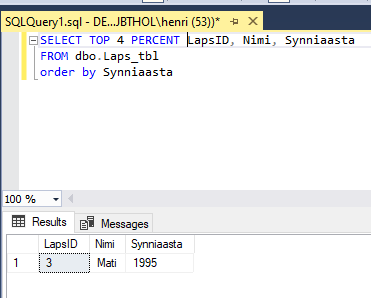
4 protsenti kuuest lapsest on küll suhteliselt tilluke arv. Aga et näidates ümardatakse arve ülespoole, siis näeme ikkagi vähemasti ühe lapse andmeid.
SQL Server 2005 täiendab TOP käsu süntaksid ühe väikese, kuid äärmiselt olulise võimalusega: nimelt on võimalik ridu piirava konstandi asemel kasutada ka muutujat või isegi alampäringut! See annab juurde väga palju uusi võimalusi päringute ja ka salvestatud protseduuride loomisel. Nii saab luua rakenduse, kus kasutaja ise ütleb, mitut rida ta soovib näha. Näiteks loome protseduuri, mis tagastab soovitud hulga vanimaid lapsi:
CREATE PROC VanimadLapsed_proc
@LasteArv int
AS
IF (@LasteArv >0)
SELECT TOP (@LasteArv) nimi, synniaasta
FROM dbo.Laps_tbl
ORDER BY synniaasta
ELSE
PRINT 'Lähteandmed päringu tegemiseks on vigased!'
Enne SQL 2005 puudus ka võimalus vahepealt valimiseks e. kui soovite tuua alates 3ndast kuni 5nda reani. SQL 2005 on tekitada tulemusse reanumbrid ning nende järgi ka filtreerida. Selleks saab kasutada ROW_NUMBER() funktsiooni.
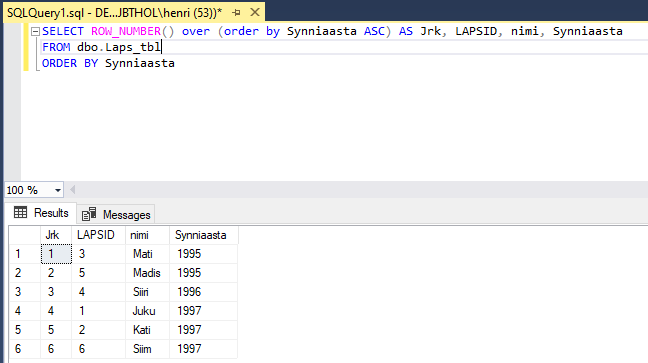
Süntaks on siis järgmine: ROW_NUMBER() OVER (partitsioon) st OVER märksõna järgi sulgudes tuleb öelda, mis moodi on read nummerdatud. Antud näites nummerdatakse sünniaastate järgi kasvavasse järjekorda.
Grupeerimine
Eelnevalt uurisime agregaatfunktsioone suurima, vähima, keskmise, summa ja koguse leidmiseks. Nad on kogu tabeli kohta head abilised. WHERE-tingimuse abil saab filtreerida sobiva tunnuse väärtuse alusel read välja ning siis nende põhjal kokkuvõtteid teha. Näiteks leida kõikide nende laste keskmise pikkuse, kes sündinud aastal 1996. Selgub aga, et käsklus lubab veelgi peenema statistika ette võtta.
Seik autori oma kogemusest. Kord oli vaja ühele firmale teha veebipõhine rakendus komandeeringuaruannete sisestamiseks ning kokkuvõtete vaatamiseks. Iseenesest pealtnäha lihtne ülesanne: igaüks annab teada, kus ta käis, mida tegi ning kui palju raha kulus ja pärast loetakse nädalate, kuude, aastate ja isikute lõikes kõikvõimalikud andmed kokku. Muuhulgas oli vaja teada, mitu korda konkreetsel aastal millist linna on komandeeringu raames külastatud. SQL oli tuttav ligikaudu samapalju, kuivõrd lugeja kirjutises siiamaani jõudes. Et ka paarilt tuttavalt nõu küsimine ei aidanud edasi, tuli ise vastav programmike kirjutada. Pool päeva tööd, paar lehekülge koodi ning tulemus oli valmis ja sobis tööandjale. Suur oli aga üllatus, kui paar päeva hiljem SQLi manuaale uurides leidus võimalus seesama töö ühe suhteliselt lihtsa lausega kirja panna.
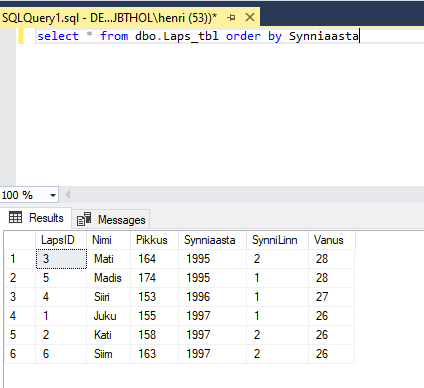
Nüüd siis mõned näited ja seletused, et siinse kirjutise lugejad ei peaks sama pikka ja okkalist teed läbi käima. Algul meeldetuletuseks laste andmed, et oleks näha, mida ja kuidas grupeeritakse.
Tahtes iga aasta kohta teada, mitu last meie nimekirjast vastaval aastal sündinud on, aitab järgnev lause. COUNT(*) loeb kokku plokis olevad read. Et päringu lõpus on GROUP BY synniaasta, siis loetakse iga erinev sünniaasta omaette plokiks. Tahtes sünniaastat ka ennast näha, tuleb ka see SELECT´i järele tulpade loetellu kirjutada. Grupeerimisfunktsioonide puhul tohibki vastusesse küsida väärtusi vaid nendest tulpadest, mille järgi grupeeritakse. Muidu tekiks ju segadus, sest kui tahaks võtta väljundisse ka pikkust, aga iga sünniaasta juurde võib kuuluda lapsi ja seega ka pikkusi mitu, siis ei tuleks vastus tabeli kujuline ning seetõttu ei sobiks relatsioonilise ehk tabelitel põhineva andmebaasi juurde. Kui aga sünniaasta järele grupeeritakse ja viimane ka ilusti näha on – siis püsib kõik korras. Pigem tunduks imelik, kui näidataks küll loendamise tulemusi 1, 3 ja 3, aga poleks näha, millise aasta juurde milline arv käib.

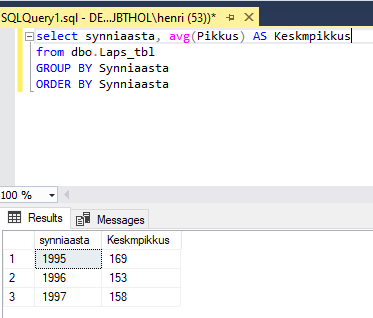
Sarnaselt nagu võib ridu kokku lugeda, saab ka teisi grupeerimisfunktsioone kasutada. Siin leitakse iga sünniaasta kohta sealsete laste keskmine pikkus.
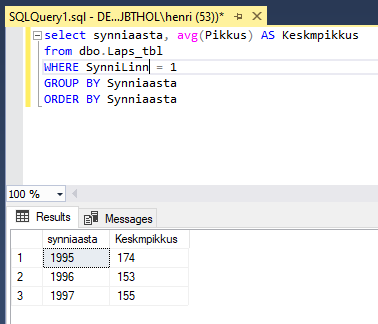
Kui rakendame päringule piiranguid WHERE abil siis esmalt filtreeritakse lähteandmed ning alles peale seda hakatakse gruppe looma:
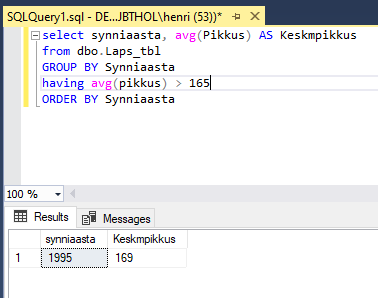
Kui soovime juba grupeeritud tulemusele piiranguid seada siis saame kasutada HAVING lauseosa. Näiteks soovime moodustada korvpallimeeskonda ning tahame teada, milliste vanusegruppide keskmine pikkus on üle 165 cm
ROLLUP, gruppide koondinfo
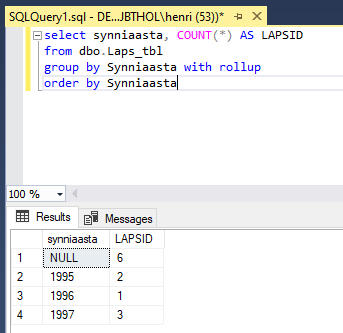
Grupeerimise juures on vahel võimalik ja vajalik päris mitmesuguseid andmeid koguda. Ja mõnikord on mugav, kui ei pea iga väärtuse jaoks omaette päringut tegema, vaid võib kõik andmed tulemusplokis ette võtta ja nendega toimetama asuda. Lihtsama näite puhul loendatakse lapsi aastate kaupa ning lõpuks võetakse kokku, palju neid üldse nimekirjas oli. Nagu alt näha – 6. Koguhulga juures pannakse sünniaasta kohale NULL, sest see ei käi enam mitte ühe konkreetse sünniaasta kohta, vaid kõigi peale kokku. Sellise lisarea annab käskluse osa WITH ROLLUP.
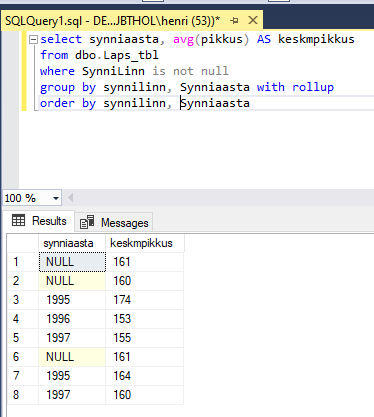
Kui grupeeritavaid tulpasid on rohkem, siis saab ka sellist lisastatistikat rohkem välja lugeda. Järgnevas näites grupeeriti lapsed sünnilinna ja sünniaasta järgi. See tähendab, et ühte gruppi sattunuksid nad vaid juhul, kui nad sündinuksid samal aastal ja oleksid ühepikkused. Iga muu kombinatsioon annab uue grupi. Nii see loend siis ka tuleb, kui algusest lugema hakata.
Kõigepealt esimeses reas teatatakse kõigi laste keskmine pikkus 167. Seejärel järgmises reas on esimese linna e. Tallinna laste keskmine pikkus 171. Seejärel tulevad keskmised pikkused Tallinna lastel, kes sündinud aastatel 1996 ja 1997. Viiendas reas on Tartu laste keskmine pikkus ning see järel aastatel 1995 ja 1997 sündinud Tartu laste keskmised pikkused.
Nagu näha tähistatakse üldkokkuvõtted määramata e. NULL väärtusega kokku võetud väljal. Võib tekkida olukord kus kokkuvõetav väli ise võib sisaldada määramata väärtuseid. Näiteks meie tabelis on ühel lapsel sünnilinn teadmata. Kui nüüd leida grupid saame tulemuseks kaks väga sarnast rida:
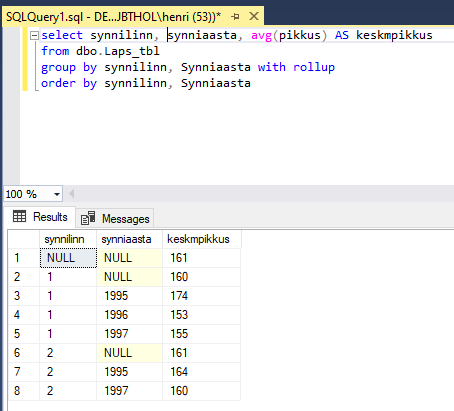
Tekib küsimus kus on kõigi laste keskmine ning kus on teadmata sünnilinnaga laste keskmine pikkus. Selle probleemi lahendamiseks saame probleemsele väljale rakendada GROUPING funktsiooni:
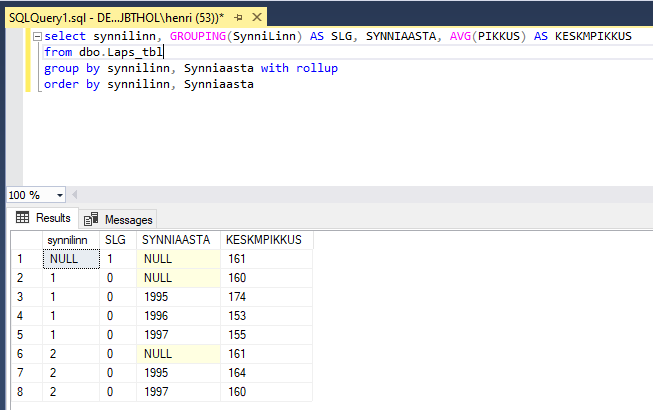
GROUPING funktsioon tekitab meile veeru, kus on 1 juhul kui on tegemist üldkokkuvõttega ning vastasel juhul on väärtus 0. Seega saame teada, et lastel kelle sünnilinna me ei tea on keskmine pikkus 165, kõigi laste keskmine pikkus on 166 ning lastel, kelle sünnilinna me ei tea ja sünniaasta on 1996 on keskmine pikkus 165.
CUBE, täiendatud koondinfo
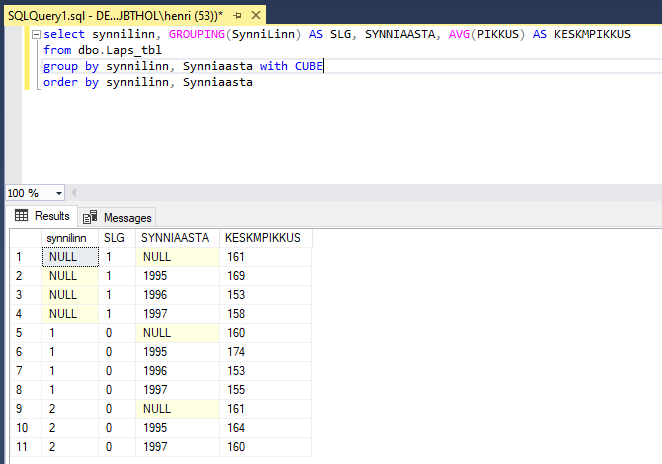
Kui eelmises päringus olnud WITH ROLLUP asendada reaga WITH CUBE, siis tehakse grupeerimist kaks korda vastupidistes suundades ning näidatakse tulemuseks neid kahte tulemust ühendatuna. Seega saame lisaks teada, et 1995 sündinute keskmine pikkus on 171, 1996 sündinutel 161 ning 1997 sündinutel 168.
Et ühe sentimeetri kaupa grupeering on nii väikese inimeste arvu puhul ilmselt liiast, võib võtta inimeste jaotuse mõnevõrra suurema piirkonna ehk detsimeetri järgi. Avaldis pikkus/10 annab täisarvude puhul jagatise täisosa. Ehk siis 157/10 annab tulemuseks 15 ja 163/10 tuleb 16. Selliselt saab lapsed 10 sentimeetri kaupa gruppidesse jagada ning grupi andmetel on juba mõnevõrra mõistlikum sisu. Et väljatrükil poleks näha mitte 15 ja 16, vaid 150 ja 160, selleks korrutati SELECT real täisarvuks muutunud jagatis uuesti kümnega. Saadud tulemustest võib välja lugeda, et 1996ndal sündinute hulgas on kaks last 150ndates ning üks 160ndates. Ning kõigi aastate peale kokku on 4 inimest 150 ja 160 vahel ning 3 inimest 160 ja 170 vahel.
Keerukamad seosed tabelite vahel
LEFT ja RIGHT JOIN
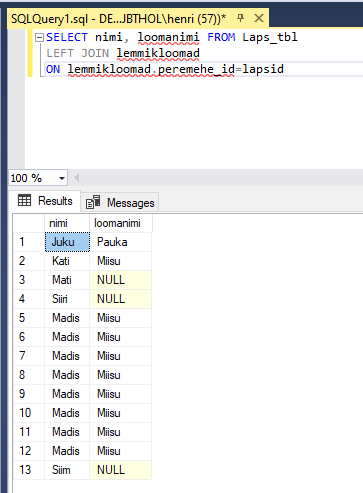
Kõige tavalisema ühendamise puhul saime kahest tabelist kätte need read, mis mõlemas olemas olid. Ehk siis loetelus olid vaid lemmikloomaga lapsed ning samuti igas loetelus olnud lemmikloomal oli kõrval peremees. Et praeguses näites ei lubata peremeheta lemmikloomi tabelisse lisada, siis jääb ära ka võimalus ülejäänud lemmikloomade näitamiseks. Küll aga võib mõnikord olla soov näha ka neid lapsi, kel pole oma koera või kassi. Ning samas loomaomanikele panna kõrvale ka loomade andmed. Sellise tööga saab hakkama LEFT JOIN. Loetelus esimesena olnud tabelist ehk vasakust näidatakse välja kõik read. Paremast aga vaid need, kus seos vasaku tabeliga olemas. Kel looma pole, sel tuleb loomanime kohale tühiväärtus NULL.
SELECT eesnimi, loomanimi FROM lapsed
LEFT JOIN lemmikloomad
ON lemmikloomad.peremehe_id=lapsed.id
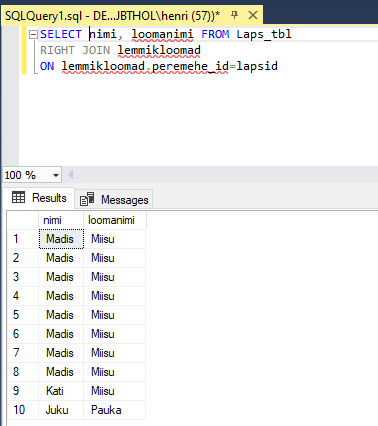
Sarnaselt töötab RIGHT JOIN. Ainult selle vahega, et näidatakse välja kõik parempoolses tabelis olevad andmed. Kui mõnele reale ei vasta kirjet vasakpoolses tabelis, siis näidatakse selle koha peal vasakpoolse tabeli väljade kohal NULL. Et siin aga on igal loomal peremees, siis tühiväärtusi ei teki.
SELECT eesnimi, loomanimi FROM lapsed
RIGHT JOIN lemmikloomad
ON lemmikloomad.peremehe_id=lapsed.id
Siiri Miisu
Siim Pauka
LEFT JOINi ja RIGHT JOINi pikem kuju on LEFT OUTER JOIN ning RIGHT OUTER JOIN. Aga nagu näha, tulemus jääb samaks.
SELECT eesnimi, loomanimi FROM lapsed
RIGHT OUTER JOIN lemmikloomad
ON lemmikloomad.peremehe_id=lapsed.id
Siiri Miisu
Siim Pauka
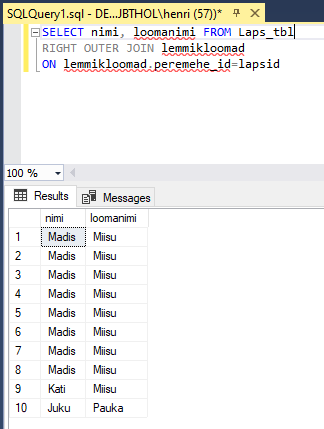
Nende ühendamiste puhul peab kindlasti silmas pidama tabelite järjekorda. Kui panna lemmikloomad vasakuks tabeliks ja lapsed parempoolseks tabeliks ning ühendamisel kasutada RIGHT JOINi ning tulbad nime järgi välja kutsuda, siis on tulemus sama, kui oleks kasutanud tabeleid teises järjekorras ning ühendamiseks LEFT JOINi.
SELECT eesnimi, loomanimi FROM lemmikloomad
RIGHT JOIN lapsed
ON lemmikloomad.peremehe_id=lapsed.id
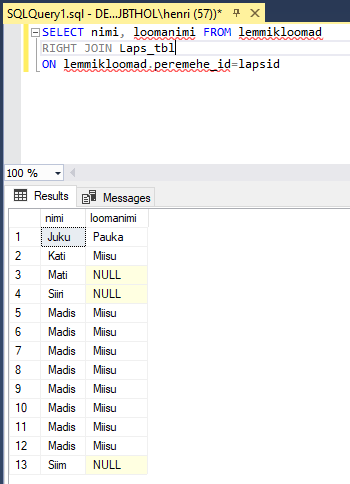
CROSS JOIN
Kõikide võimalike kombinatsioonide väljatrükiks sobib CROSS JOIN. Sel juhul võtmeid tabelite ühendamiseks ei kasutata, vaid trükitakse välja kõik võimalikud kombinatsioonid, kuidas esimese tabeli read saavad olla ühendatud teise tabeli ridadega. Ehk siis siin näites pakutakse välja kõik kombinatsioonid, milline laps saab millise lemmikloomaga koos olla.
SELECT eesnimi, loomanimi FROM lemmikloomad
CROSS JOIN lapsed
Juku Miisu
Kati Miisu
Mati Miisu
Ats Miisu
Siiri Miisu
Siim Miisu
Mari Miisu
Juku Pauka
Kati Pauka
Mati Pauka
Ats Pauka
Siiri Pauka
Siim Pauka
Mari Pauka
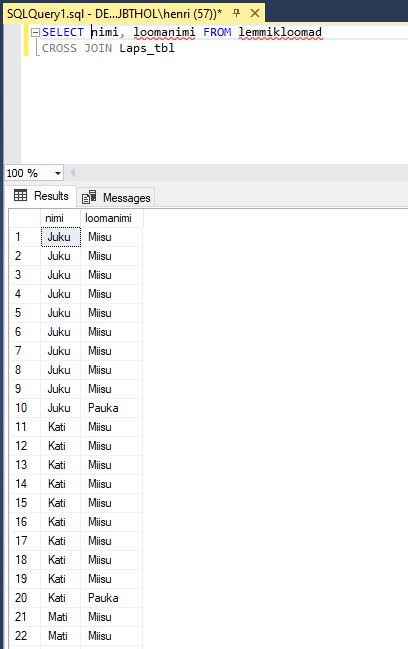
Eks sellist segapudru läheb suhteliselt harvem vaja, aga ilus on vaadata, kes võib kellega koos olla. Samuti sobib CROSS JOIN olukordade jaoks, kui tahetakse kõikide võimalike variantide hulgast sobivat välja otsida. Näiteks soovitakse otsida kombinatsioonid, kus lapse ja looma nimed algavad sama tähega, või siis on nad sündinud samas kuus. Siinse näite puhul on tingimused pastakast välja imetud, aga mõne tutvumisõhtu puhul või laborikatsete juures võivad sellised valikud täiesti omal kohal olla.
CROSS JOINiga sama tulemuse annab, kui päringusse kirjutada lihtsalt tabelite nimed ilma täiendavaid tingimusi seadmata.
SELECT eesnimi, loomanimi FROM lemmikloomad, lapsed
Juku Miisu
Kati Miisu
Mati Miisu
Ats Miisu
Siiri Miisu
Siim Miisu
Mari Miisu
Juku Pauka
Kati Pauka
Mati Pauka
Ats Pauka
Siiri Pauka
Siim Pauka
Mari Pauka
Seos sama tabeliga
Esimese hooga võib tunduda imelik, miks peaks olema vaja siduda tabelit iseenesega. Aga rakendusi kirjutades tekib selliseid seostamiskohti üllatavalt palju. Näiteks kui kataloogid on kataloogipuus, siis seda struktuuri saab tabelisse salvestada nii, et iga kataloogi puhul kirjutatakse eraldi tulpa tema ülemkataloogi ID. Ning juurkataloogi puhul see arv näitab iseenesele või ei näita kuhugi. Samuti foorumi kirjade puhul, kui tahetakse meeles pidada, milline kiri millisele vastab. Siin aga vaatame, kuidas seos sama tabeliga toimub sünniaastate kaudu. Esialgu koostatakse päring, kus näidatakse kõikide laste paarid nendega samal aastal sündinud lastega. Et saaks tabelit iseenesega seostada, tuleb tabelist teha päringu ajaks kaks koopiat. Nii nagu sai päringus tulpasid ümber nimetada, nii saab ümber nimetada ka tabeleid.
SELECT * FROM lapsed as tabel1, lapsed as tabel2
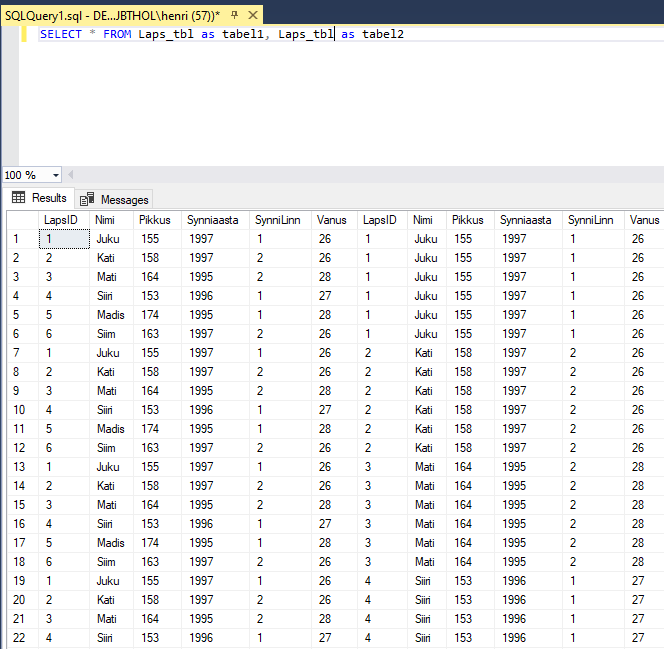
ütleb, et võta tabel lapsed kõigepealt märksõna all tabel1 ning seejärel tabel lapsed ka märksõna all tabel2. Edasi juba võib need tabelid tingimus(t)e abil kokku siduda, sest muidu näidataks kõikide ridade omavahelised võimalikud kombinatsioonid. Et siin aga soovime paare vaid sünniaastate kaupa, siis nõuame, et eri tabeli ridade kõrvuti panekuks peavad nende laste sünniaastad kattuma.
SELECT * FROM lapsed as tabel1, lapsed as tabel2
WHERE tabel1.synniaasta=tabel2.synniaasta

Üllatusena avastame, et Juku paariliseks on pandud ka Juku ise. Ning paarina on olemas nii Juku Katiga kui Kati Jukuga. Selliseid anomaaliaid saab tingimuste täpsustamisega vähendada või kaotada.
Kui soovida, et sama isik ei oleks iseenesega kõrvuti, siis aitab tingimus, et kõrvuti seatud tabelikoopiate id-numbrite väärtused ei oleks võrdsed. Kui soovida, et sama paari korduvalt ei näidataks, siis võib seada näiteks tingimuse, et teisest tabelist tuleva inimese id-number oleks suurem kui esimesest tabelist tulev id-number. Sellisel juhul jääb igast paarist alles vaid üks väljatrükk – selline, mis vastab tingimustele.
Tahame ainult ühe konkreetse isiku eakaaslasi kätte saada, võib tema eraldi ära määrata. Kindlam oleks küll id kaudu, sest mitme Juku puhul võivad tekkida segadused. Meil aga on vaid üks Juku, seetõttu on loota, et vastus sobib ning tema eakaaslasteks on siin tabelis vaid Kati ja Siim.
SELECT tabel2.eesnimi from lapsed as tabel1, lapsed as tabel2
WHERE tabel1.synniaasta=tabel2.synniaasta
AND tabel1.id<>tabel2.id and tabel1.eesnimi='Juku'
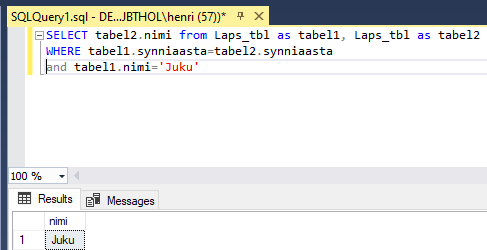
Vastuses oleva tulba nimi võetakse esimese päringu järgi. Ja ongi kõik erinevad nimed siin.
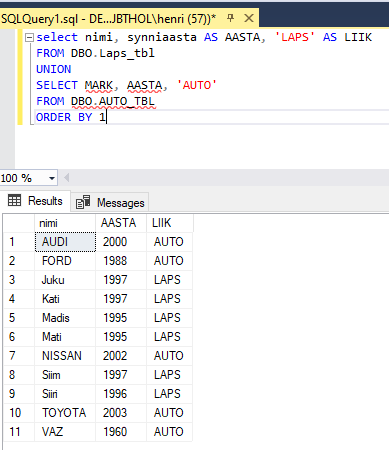
select nimi, synniaasta AS AASTA, 'LAPS' AS LIIK
FROM DBO.Laps_tbl
UNION
SELECT MARK, AASTA, 'AUTO'
FROM DBO.AUTO_TBL
ORDER BY 1
Sarnase pikkusega lapsed
Järgnevalt mõned näited, kuidas sama ülesannet saab alampäringute abil mitmel moel rakendada. Lisatud näited on tehtud ühe tabeli andmete põhjal. Vähegi suuremas andmebaasis aga käiakse väärtusi sageli küllalt kaugelt küsimas.
Läbimängitava ülesandena otsitakse tabelist iga lapse kohta, kui palju on temaga sarnase pikkusega teisi lapsi. See tähendab arvuti keeles, et otsitakse iga lapse puhul, mitu on neid lapsi, kelle pikkus erineb temast mitte rohkem kui ühe sentimeetri võrra. Üheks võimaluseks on teha lihtsalt eraldi tulp. Selles tulbas väärtuse leidmiseks tuleb andmebaasimootoril igal korral vastav päring uuesti käivitada. Iga kord, kui välimises päringus võetakse ette uus inimene, loetakse kolmanda tulba ehk sarnase pikkusega laste leidmiseks uuesti kokku kõik lapsed, kelle pikkuse erinevust just sellest konkreetsest trükitavast lapsest on 1 sentimeeter või vähem. ABS tähendab absoluutväärtust. Miinus üks tulbaavaldise lõpus on vajalik, kuna trükitav laps loetakse alampäringu abil ka ise iseendaga ühepikkuste laste hulka. Et igaüks on enesega sama pikk, saabki lahutamistehte abil väärtuse õigeks.
SELECT eesnimi, pikkus,
(
SELECT COUNT(*) FROM lapsed as tabel2
WHERE ABS(tabel2.pikkus-tabel1.pikkus)<=1
)-1 as sarnaseid
FROM lapsed as tabel1
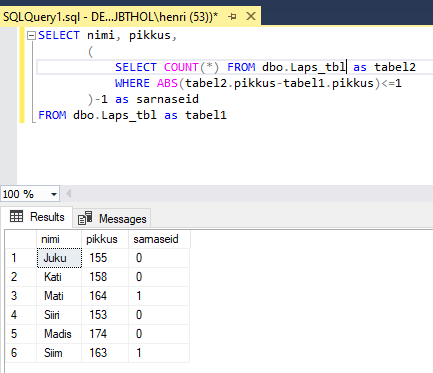
Tollest miinus ühest saab vabaneda, kui eraldi tingimusse lisada, et trükitavat last ennast samapikkade laste kokku lugemisel ei arvestata. Ehk siis trükitava lapse id (tabel1.id) ning loetava lapse id (tabel2.id) ei tohi kattuda.
SELECT eesnimi, pikkus,
(
SELECT COUNT(*) FROM lapsed as tabel2
WHERE ABS(tabel2.pikkus-tabel1.pikkus)<=1
AND tabel1.id<>tabel2.id
) as sarnaseid
FROM lapsed as tabel1
Ehkki kood läks veidi pikemaks, võib see hiljem paremini loetav olla. Sest salapärane -1 võib võõrale lugedes päris palju peavalu valmistada. Kui aga ilusti tingimuse abil kontrollitakse, et trükitav tegelane ei oleks kokkuloetavate hulgas – see on loodetavasti kergemini mõistetav. Tulemused on samad nagu eelmise päringu korral.
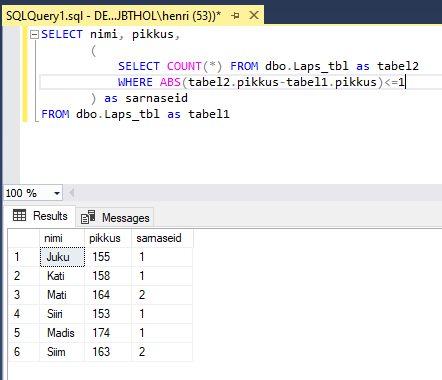
Ehkki kood läks veidi pikemaks, võib see hiljem paremini loetav olla. Sest salapärane -1 võib võõrale lugedes päris palju peavalu valmistada. Kui aga ilusti tingimuse abil kontrollitakse, et trükitav tegelane ei oleks kokkuloetavate hulgas – see on loodetavasti kergemini mõistetav. Tulemused on samad nagu eelmise päringu korral.
Järgnevalt kasutame pikkuskaimude leidmiseks EXISTS-lauset päringu tingimusosas. Kui ennist loeti kokku, mitu sobiva pikkusega kaaslast leiti, siis siin küsitakse iga uuritava lapse puhul soovitud tingimusele vastavad kaaslased. Pikkuskaimu leidumise korral on EXISTS-kontrolli tingimus tõene ning vastava eesnime ja sünniaasta võib välja kirjutada.

Sama ülesande võib lahendada veel kolme SELECT´i abil. Algus on sarnane nagu esimeses näites, kus trükkimise kolmandas tulbas arvutati välja, mitu pikkuskaimu iga lapse puhul on. Kuid kui nüüd me ei taha saada mitte arvu, vaid loetelu nendest, kel kaimud olemas, siis saab väljastatud tabelile lihtsalt veel ühe päringu ümber panna. Eesnimi ja pikkus väljastatakse ka välimises päringus. Kolmanda tulba ehk “sarnaseid” väärtust aga kasutatakse otsustamiseks, kas vastavat rida näidata või mitte.
SELECT eesnimi, pikkus FROM
(SELECT eesnimi, pikkus,
(
SELECT COUNT(*) FROM lapsed as tabel2
WHERE ABS(tabel2.pikkus-tabel1.pikkus)<=1
AND tabel1.id<>tabel2.id
) as sarnaseid
FROM lapsed as tabel1
)as tabel3
WHERE tabel3.sarnaseid>0
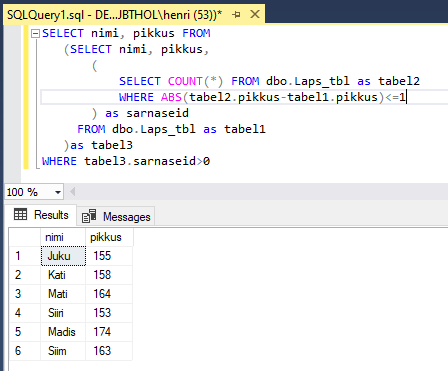
Veeru asendaja
Kontroll IN võimaldab tingimuses uurida, kas otsitav väärtus kattub mõnega teises päringus väljastatud väärtustest. Siinsel juhul siis sisemises päringus leitakse kõik 1997. aastal sündinud laste pikkused. Edasi välimises päringus väljastatakse kõikide laste andmed, kelle pikkus kattub kasvõi ühega eelpoolleitud pikkustest.
SELECT eesnimi, synniaasta FROM lapsed
WHERE pikkus IN (
SELECT pikkus FROM lapsed
WHERE synniaasta=1997
)
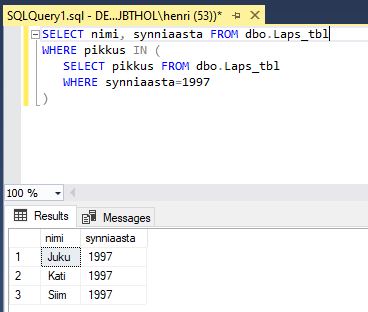
Nagu tulemustest näha, on tulemusridade hulgas lisaks 1997. sündinutele ka üks 1996. aastal sündinu, kel pikkust samapalju kui mõnel aasta nooremal. Tõepoolest – Mari ja Kati on ühepikkused. Ehkki esimene neist sündinud 1996. ning teine 1997. aastal.
Tekkinud tabelite ühendamine
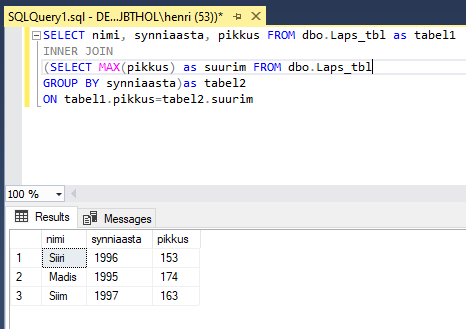
Ka alampäringus tekkinud tabeleid saab teistega ühendada sarnaselt tavalistele võimalustele. Siin leitakse tagumises päringus iga sünniaasta kohta suurim pikkus. Ning tabelite ühendamise kaudu (ehkki praegu ühendatakse laste tabelist saadud tulemus algse tabeli enesega) leitakse iga suurima pikkuse kohta inimese nimi ja sünniaasta, kellel selline pikkus on. Juhul, kui juhtuks aastakäigu suurima pikkusega olema võrdselt mitu inimest, siis trükitaks nad kõik nagu tabelite ühendamise puhul kombeks.
SELECT eesnimi, synniaasta, pikkus FROM lapsed as tabel1
INNER JOIN
(SELECT MAX(pikkus) as suurim FROM lapsed
GROUP BY synniaasta)as tabel2
ON tabel1.pikkus=tabel2.suurim
Common Table Expression
Common Table Expression CTE on väga sarnane ajutisele vaatele, mida saab kasutada päringu FROM lauseosas.
Üldine süntaks näeb välja järgmine:
WITH <CTE nimi>(<väljanimed>)
AS
(
<tegelik päring>
)
SELECT * FROM <CTE nimi>
CTE abil on võimalik vältida ajutiste tabelite ning alampäringute kasutamist. See omakorda muudab päringu ülevaatlikumaks ning lihtsamaks.
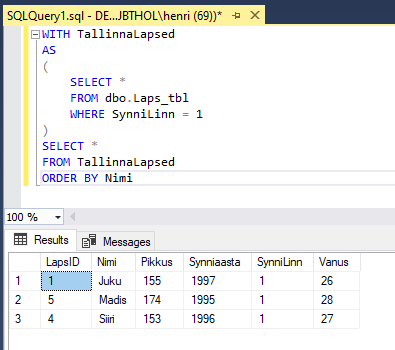
Näiteks soovime tegelda ainult Tallinnas (kood 1) sündinud lastega. Sellisel juhul saame endale kirjeldada CTE, milles sisalduvad vaid Tallinna lapsed ning kasutada seda oma päringus nagu iga teist tabelit või vaadet:
WITH TallinnaLapsed
AS
(
SELECT *
FROM dbo.Laps_tbl
WHERE SynniLinn = 1
)
SELECT *
FROM TallinnaLapsed
ORDER BY Nimi
tulemus:
CTE tõeline jõud tuleb aga ilmsiks kui läbi rekursiivsete päringute. Rekursiivsed SQL päringud olid ka põhiline idee CTE loomise taga.
Rekursiivse päringu loomiseks tuleb CTE tekitada UNION päringu abil, milles on kaks liiget ankur (alguspunkt päringule) ning rekursiivne liig (iseendale viitav päring).
Et seda katsetada teeme mõned täiendused oma Laste tabelisse ning lisame sinna uue välja Rühmajuht ning määrame igale lapsele sobiva juhi:
— Lisame tabelisse uue välja
ALTER TABLE dbo.Laps_tbl
ADD Ryhmajuht INT NULL REFERENCES dbo.Laps_tbl (LapsID)
GO
— paneme rühmajuhtideks igas linnas esimese kõige vanemate linnakodanike hulgast
WITH VanimSynniA AS
( -- Iga linna varaseim sünniaasta
SELECT SynniLinn, MIN(SYNNIAASTA) AS Aasta
FROM dbo.Laps_tbl AS L1
GROUP BY SynniLinn
),
Pealikud AS
( -- esimene väikseima sünniaastaga laps
SELECT L2.SynniLinn, MIN(L2.LapsID) AS LapsID
FROM dbo.Laps_tbl AS L2
INNER JOIN VanimSynniA as VA ON L2.SynniLinn = VA.SynniLinn AND L2.SynniAasta = VA.Aasta
GROUP BY L2.SynniLinn
)
UPDATE dbo.Laps_tbl
SET Ryhmajuht = P.LapsID
FROM dbo.Laps_tbl AS L3
INNER JOIN Pealikud AS P ON L3.SynniLinn = P.SynniLinn
WHERE L3.LapsID <> P.LapsID
GO
-- Määrame ka peetri kahe lapse rühmajuhiks
UPDATE dbo.Laps_tbl
SET RyhmaJuht = 12
WHERE LapsID IN (2,10)
-- lisame uue Lapse, kellest saab suurib pealik
DECLARE @UusLapsID INT
INSERT INTO dbo.Laps_tbl (Nimi, Synniaasta)
VALUES ('Roobert', 1988)
SET @UusLapsID = @@identity
UPDATE dbo.Laps_tbl
SET Ryhmajuht = @UusLapsID
WHERE Ryhmajuht IS NULL AND LapsID <> @UusLapsID
Kui kõik tehtud on meie tabel järgmine:
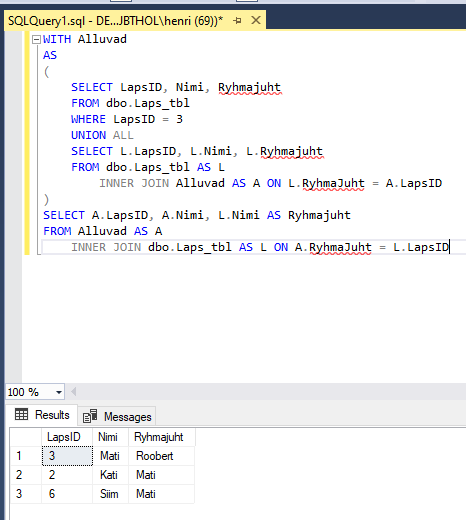
Alustame hästi lihtsast rekursiivsest päringust püüdes välja selgitada, kes alluvad Matile:
WITH Alluvad
AS
(
SELECT LapsID, Nimi, Ryhmajuht
FROM dbo.Laps_tbl
WHERE LapsID = 3
UNION ALL
SELECT L.LapsID, L.Nimi, L.Ryhmajuht
FROM dbo.Laps_tbl AS L
INNER JOIN Alluvad AS A ON L.RyhmaJuht = A.LapsID
)
SELECT A.LapsID, A.Nimi, L.Nimi AS Ryhmajuht
FROM Alluvad AS A
INNER JOIN dbo.Laps_tbl AS L ON A.RyhmaJuht = L.LapsID
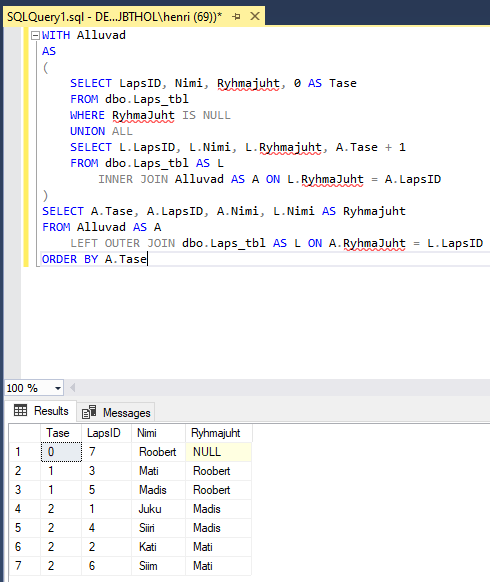
Järgmisena alustame uuringut kõige suurematest pealikest e. kellel Rühmajuht puudub ning püüame välja selgitada mitmenda taseme alluvaga on tegemist:
WITH Alluvad
AS
(
SELECT LapsID, Nimi, Ryhmajuht, 0 AS Tase
FROM dbo.Laps_tbl
WHERE RyhmaJuht IS NULL
UNION ALL
SELECT L.LapsID, L.Nimi, L.Ryhmajuht, A.Tase + 1
FROM dbo.Laps_tbl AS L
INNER JOIN Alluvad AS A ON L.RyhmaJuht = A.LapsID
)
SELECT A.Tase, A.LapsID, A.Nimi, L.Nimi AS Ryhmajuht
FROM Alluvad AS A
LEFT OUTER JOIN dbo.Laps_tbl AS L ON A.RyhmaJuht = L.LapsID
ORDER BY A.Tase
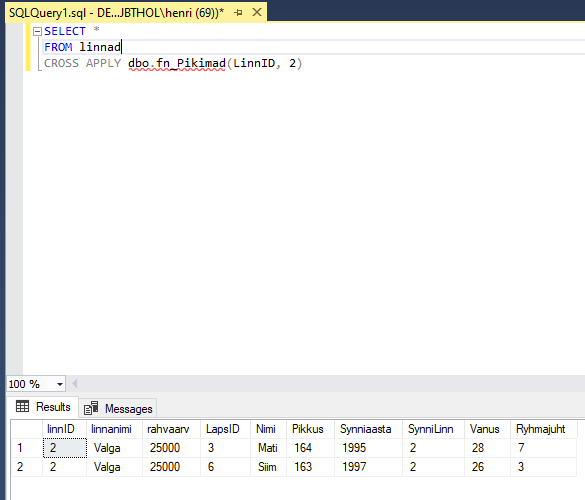
APPLY
APPLY on uus operaator FROM lauseosas, mis võimaldab Teil teha väljakutseid tabelit tagastavatele funktsioonile iga rea kohta peapäringus.
Näiteks huvitavad, meid iga linna kõige pikemad lapsed. Selleks loome funktsiooni, mis loetleb meile ülesse konkreetse linna kõige pikemad lapsed:
CREATE FUNCTION dbo.fn_Pikimad (@LinnID int, @Top int)
RETURNS TABLE
AS
RETURN SELECT TOP (@Top) *
FROM dbo.Laps_tbl
WHERE SynniLinn = @LinnID
ORDER BY Pikkus DESC
Selleks, et vaadata seda infot konkreetsete linnade kaupa saame kirjutada päringu:
Nummerdamised
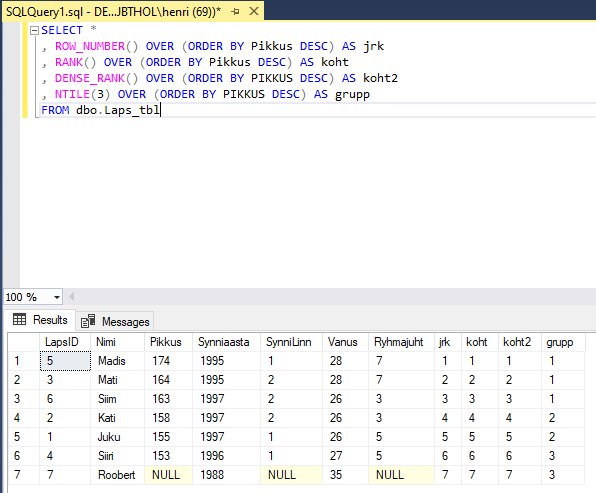
ROW_NUMBER() – nummerdab kõik read tulemuses
RANK() – ütleb, mitmes on loetelus antud väärtus
DENSE_RANK() – analoogne RANK funktsiooniga, kuid ei jäta numbreid vahele
NTILE(n) – jagab tulemuse N grupiks
SELECT *
, ROW_NUMBER() OVER (ORDER BY Pikkus DESC) AS jrk
, RANK() OVER (ORDER BY Pikkus DESC) AS koht
, DENSE_RANK() OVER (ORDER BY PIKKUS DESC) AS koht2
, NTILE(3) OVER (ORDER BY PIKKUS DESC) AS grupp
FROM dbo.Laps_tbl
SELECT *
, ROW_NUMBER() OVER (partition BY RymnaJuht order by pikkus DESC) AS jrk
, RANK() OVER (partition BY RyhmaJuht order by Pikkus DESC) AS koht
, DENSE_RANK() OVER (partition BY RyhmaJuht order by PIKKUS DESC) AS koht2
, NTILE(3) OVER (ORDER BY PIKKUS DESC) AS grupp
FROM dbo.Laps_tbl
ORDER BY RyhmaJuht, pikkus desc